A Modern Deployment Pipeline
Yet another Deployment Pipeline
(But this one is cool I promise)
Hackernews and /r/devops has been littered with posts about companies bragging about their deployment pipelines.
It’s cool to read what other people are doing. That’s how we improve. The less hacky the better!
I’ve seen pure chef deployments where the entire infrastructure, provisioning, and post-deploy was managed by chef.
I’ve seen fabric scripts that do everything by importing boto for setting up the AWS infrastructure and creating the AMI’s.
 _This looks like nightmare soup_
_This looks like nightmare soup_
I think Hashicorp has the right idea. Atlas is their Enterprise version of what I pieced together here.
So before I begin, let me show an overview of what this looks like:
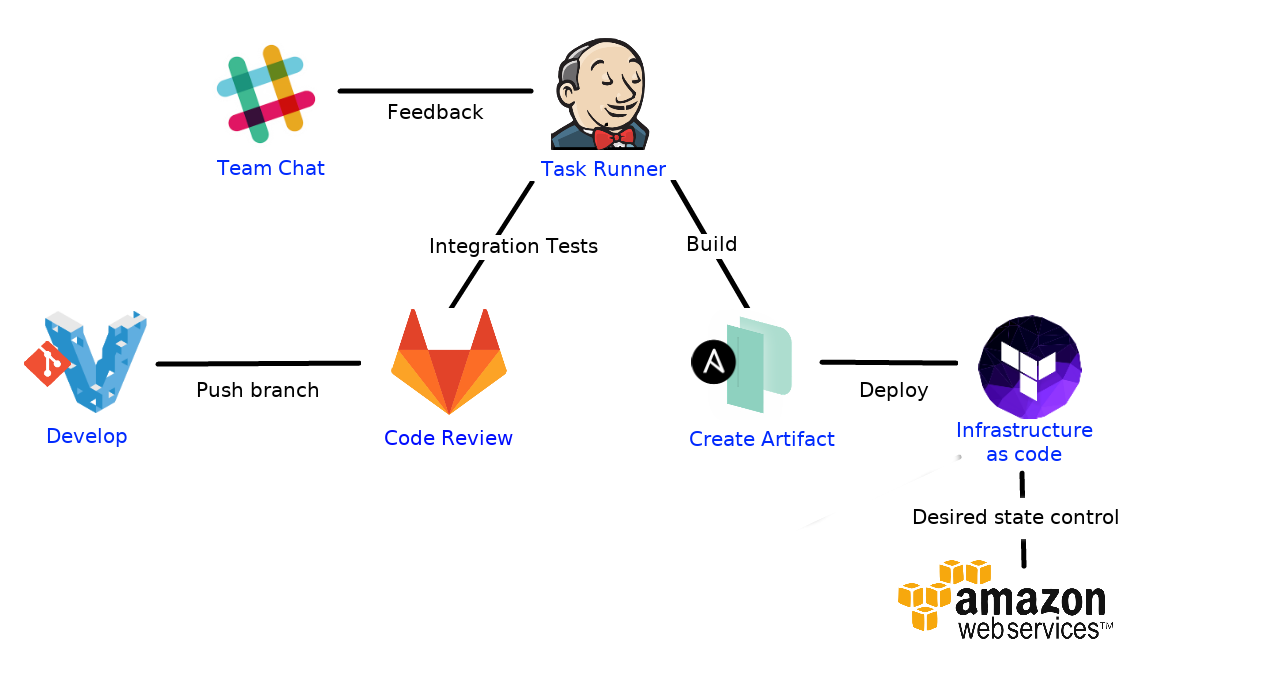
- Vagrant for Developing
- Gitlab for Version Control Interface (or Github, Bitbucket, git in the raw)
- Jenkins for kicking off builds and tasks (I’ve been using gitlab-ci lately)
- Packer to build the artifact
- Terraform to create the infrastructure
Vagrant
vagrant up and boom, done. It spins up a virtual machine for your to play around in. You have your entire development environment.
I don’t like pre-baked vagrant boxes. I usually use vanilla ubuntu and use a provisioner tool like ansible or some simple shell scripts.
If you have lots of dependent services, then this will get complicated quickly. A project of mine requires an ES host, redis, mongodb, and the web application itself.
We ended up using docker-compose to bring up that stack very quickly. You could run those in a multi-box vagrant setup, but that means running 4 VMs at once.
Packer
Image creation is a numbing task if you have to do it a lot. Most people create automated scripts to do the provisioning part, but they still create the VM’s and capture the image manually. That’s where Packer comes in.
If you want an AWS AMI, Packer will:
- Spin up an instance
- Create the temporary security group and SSH keys
- Provision your application (chef, ansible, scripts, etc…)
- Save the AMI
- Destroy what it created to save the AMI
I first used Packer to create qcow2 images from a base Ubuntu ISO and upload the image to proxmox.
Check out all the builders that Packer supports.
Terraform
Now you have an image of your application, let’s run it!
Well hold up, a lot goes into just “running” a machine image in an production environment. You probably want load balancers, scaling groups, firewall rules, DNS changes, and other services running.
Terraform is made for the job. Infrastructure as Code.
Changing firewall rules is just a pull request away.
Imagine changing your entire cloud provider by changing a configuration file.
The Future is Now
The language isn’t anything crazy. Very easy to read and write. It’s basically just:
resource "aws_elb" "frontend" {
name = "frontend-load-balancer"
listener {
instance_port = 8000
instance_protocol = "http"
lb_port = 80
lb_protocol = "http"
}
instances = ["${aws_instance.app.*.id}"]
}
resource "aws_instance" "app" {
count = 5
ami = "ami-408c7f28"
instance_type = "t1.micro"
}
Tons of providers, including Digital Ocean:
resource "digitalocean_droplet" "web" {
name = "tf-web"
size = "512mb"
image = "centos-5-8-x32"
region = "sfo1"
}
resource "dnsimple_record" "hello" {
domain = "example.com"
name = "test"
value = "${digitalocean_droplet.web.ipv4_address}"
type = "A"
}
Don’t think that Terraform can’t handle big boy things. Examples on their site.
It can also control state cross-provider. You can create machines in AWS, run services in GCE, and update your DNS in DNSimple.
Jenkins
Most web-based repository managers like Gitlab have webhooks or plugins to a CI server like Jenkins. To do your application testing, just add the webhook and setup your task on the CI to run on merge requests.
As for deployment, you can have it trigger on tag pushes or leave out the webook all together.
The deployment task will end up looking something like this:
Step 1
#!/bin/bash -xe
cd $WORKSPACE/ops
REVISION=`git describe --abbrev=0 --tags`
packer-io build -machine-readable \
-var 'config=~/confs/app.conf.prod' \
-var 'provision_type=prod' \
-var "revision=$REVISION" \
packer.json | tee build.log
AMI=`grep 'artifact,0,id' build.log | cut -d, -f6 | cut -d: -f2`
rm build.log
echo AMI=$AMI > prod_propsfile
echo REVISION=$REVISION >> prod_propsfile
[env vars inject plugin for prod_propsfile]
Step 2
#!/bin/bash -xe
cd $WORKSPACE/ops/terraform/prod
terraform remote pull
terraform plan -var "ami=$AMI" -var "revision=$REVISION" deploy
terraform apply -var "ami=$AMI" -var "revision=$REVISION" deploy
terraform remote push
For Gitlab-CI, it will be the same commands in a script: section.
Closing Thoughts
I like that this pipeline isn’t married to any cloud solution or configuration management framework.
Packer can create vmdk images using chef and Terraform can create the infrastructure and launch the VM on Vsphere. In experimentation I’ve used Packer to create Docker images and used Terraform to load them onto a container cluster in Google Compute Engine.
I still can’t figure out how to manage secrets properly. I’ve been using Hashicorp’s Vault, but I’ve been having weird errors. Another blog post for another time.
The tools are changing every day in this field. I’m looking at otto right now. A month after this blog post I could be using an entirely different pipeline.
Want to tell me this is a stupid way of deploying? Email or hit me up on twitter @thatarchguy